llvm&ollvm初探
LLVM
LLVM的核心思想是将编译器分为前端和后端两个部分,前端负责将源代码转换为中间表示LLVM Intermediate Representation (IR)(以库的形式提供接口),后端负责将中间表示转换为目标机器的汇编代码。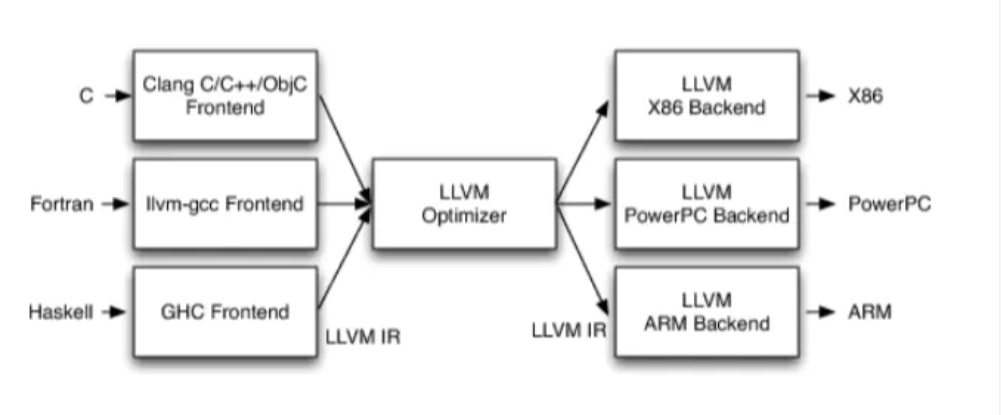
LLVM IR
三种表示:
- .ll 格式:人类可以阅读的文本。
- .bc 格式:适合机器存储的二进制文件。
- 内存表示
LLVM Pass
https://llvm.org/docs/WritingAnLLVMPass.html#the-immutablepass-class
Pass就是“遍历一遍IR,可以同时对它做一些操作”的意思,Pass 是 中间 IR 处理环节的主要模块。
llvm pass的作用:
- 插桩
- 优化机器无关的代码
ModulePass (基于模块)
如果函数传递不需要任何模块或不可变传递,则模块传递可以使用接口的函数级传递(例如支配者)来提供检索分析结果的函数。
FunctionPass (基于函数)
CallGraphPass (基于调用图)
LoopPass (基于循环)
PASS 注册方式
1、修改 PassRegistry.def 和 PassBuilder.cpp 文件,直接追加 Pass 定义进去。
2、是用插件接口进行注册
LLVM Pass 实现「指令替代混淆」
| 步骤 | 操作 |
|---|---|
| 注册 | 通过 llvmGetPassPluginInfo() 注册 |
| 遍历 | 遍历 Function / BasicBlock |
| 修改 | 进行 IR 控制流改造(添加跳转 / switch / 伪逻辑) |
- Pass 的注册方式:插件式注册,使用 llvmGetPassPluginInfo() 提供插件信息给 LLVM。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20extern "C" LLVM_ATTRIBUTE_WEAK ::llvm::PassPluginLibraryInfo
llvmGetPassPluginInfo() {
return {LLVM_PLUGIN_API_VERSION, //llvm 版本号环境取值
"mba-sub", //插件名字
LLVM_VERSION_STRING, //插件版本号 都是随便传
[](PassBuilder &PB) { // 第四个是一个回调,
// 用于告诉 PassBuilder:当用户传了 "mba-sub" 时,就注册你自己的 MBASub Pass。
PB.registerPipelineParsingCallback(
[](StringRef Name, FunctionPassManager &FPM,
ArrayRef<PassBuilder::PipelineElement>) {
if (Name == "mba-sub") {
FPM.addPass(MBASub());
//FPM.addPass (MBASub ()) 这行代码向函数级别 Pass 管理器 FPM 中添加了一个 MBASub Pass 的实例。
// 在这里,MBASub () 表示创建了 MBASub 结构体的一个实例 (默认构造函数),并将其添加到 Pass 管理器中
return true;
}
return false;
});
}};
}
1 | opt -load-pass-plugin ./libMBASub.so -passes=mba-sub < input.ll > output.ll |
定义 Pass 本体(MBASub)
定义了一个结构体MBASub,继承自llvm::PassInfoMixin<MBASub>1
2
3
4
5
6
7
8struct MBASub : public llvm::PassInfoMixin<MBASub> {
llvm::PreservedAnalyses run(llvm::Function &F, llvm::FunctionAnalysisManager &);
//run() 是入口,遍历函数中所有基本块
bool runOnBasicBlock(llvm::BasicBlock &B);
//runOnBasicBlock() 实际处理每个基本块中的指令;
static bool isRequired() { return true; }
//isRequired() 返回 true 表示这个 Pass 默认启用(不是分析 Pass)。
};指令替换核心逻辑:将 a - b 替换为 (a + ~b) + 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22bool MBASub::runOnBasicBlock(BasicBlock &BB) {
for (auto Inst = BB.begin(); Inst != BB.end(); ++Inst) {
auto *BinOp = dyn_cast<BinaryOperator>(Inst);
//dyn_cast<BinaryOperator>:从通用 Instruction 类型动态转为二元操作类型;
if (!BinOp) continue;
unsigned Opcode = BinOp->getOpcode(); //getOpcode() 判断是不是 sub 指令;
if (Opcode != Instruction::Sub || !BinOp->getType()->isIntegerTy())
continue;
IRBuilder<> Builder(BinOp); //IRBuilder<> 用于构造 IR 新指令;
Instruction *NewValue = BinaryOperator::CreateAdd(
Builder.CreateAdd(BinOp->getOperand(0),
Builder.CreateNot(BinOp->getOperand(1))),
ConstantInt::get(BinOp->getType(), 1));
ReplaceInstWithInst(&BB, Inst, NewValue);
//使用 ReplaceInstWithInst() 替换原始指令。
}
return Changed;
}
ollvm
虚假控制流 BCF (Bogus Control Flow)
原理:
- 虚假控制流混淆通过加入包含不透明谓词的条件跳转(永真or永假)和不可达的基本块,来干扰 IDA 的控制流分析和 F5 反汇编。
反混淆:
1、将全局变量赋值并将 segment 设为只读。
- 对于常规的 ollvm 的 bcf 混淆来说,bcf 的不透明谓词都是处于 .bss段 中。
- Edit->Segments->Edit segment 将 Write 复选框取消勾选, .bss段 就设为只读
2、d810
3、idapython patch 不透明谓词
指令替换(Instruction Substitution)
原理:
- 用于将程序中的原始指令替换为等效但更难理解和还原的指令序列。
反混淆:
1、d810
2、GAMBA
控制流平坦化(FLA)
原理:
- 通过一个主分发器来控制程序基本块的执行流程
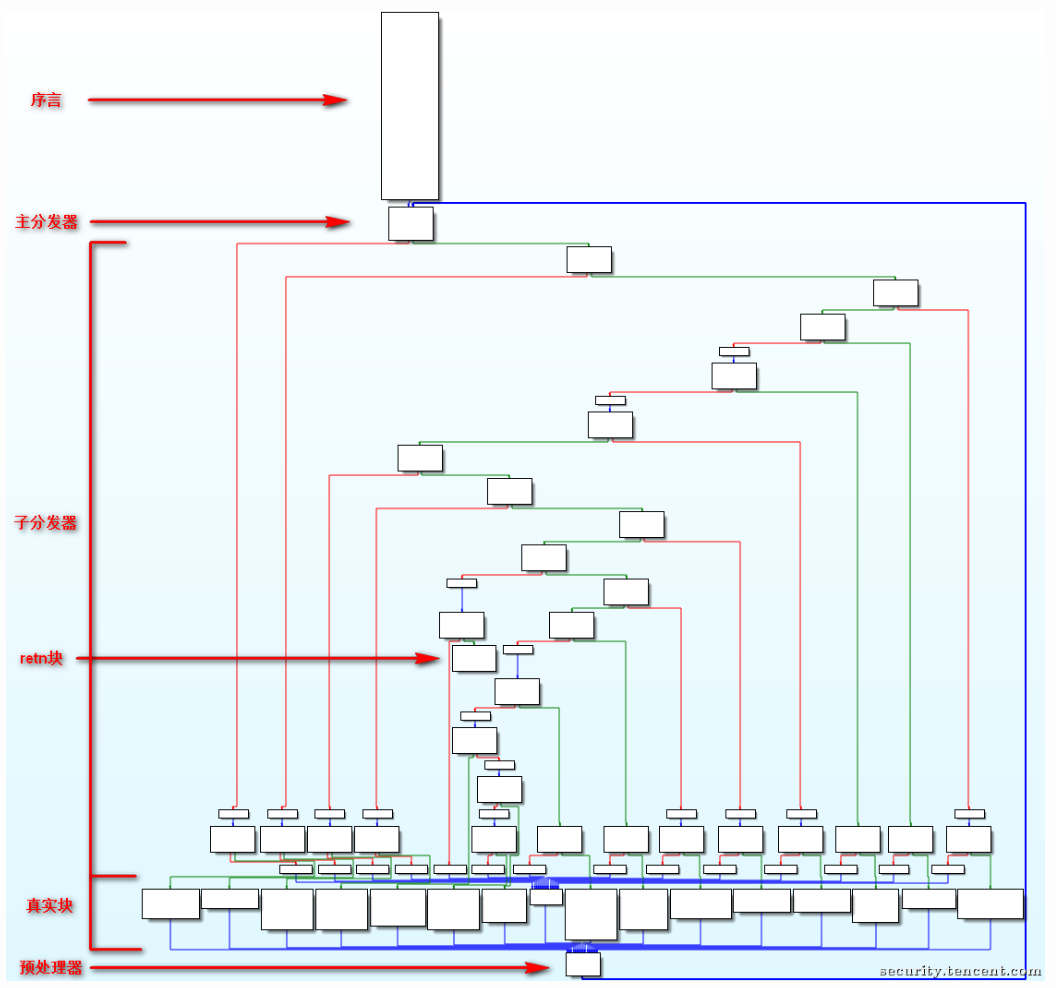
- 序言:函数的第一个执行的基本块
- 主 (子) 分发器:控制程序跳转到下一个待执行的基本块
- retn 块:函数出口
- 真实块:混淆前的基本块,程序真正执行工作的块
- 预处理器:跳转到主分发器
各块之间的规则:
- 函数的开始地址为序言的地址
- 序言的后继为主分发器
- 后继为主分发器的块为预处理器
- 后继为预处理器的块为真实块
- 无后继的块为retn块
- 剩下的为无用块
反混淆:
1、找到真实块。手撕;idapython 通过各个块之间的联系通过一定的规则找真实块;可以用 unicorn 或 angr 得到函数的 CFG, 利用规则匹配出真实块…
方法多种多样,但是核心都是找到真实块,除真实块和序言块外,其余的块都是虚假块,我们需要 NOP 掉他们。
2、得到真实块之间的联系。模拟执行pr真机调试打断点 trace。
3、用跳转汇编指令将每个真实块串起来。
字符串加密
原理:
- 编写一个pass将其中的字符串信息使用一些加密算法进行加密,然后特定的时间进行还原。一般含有字符串混淆、函数名混淆、不在init_array解密等。
反混淆:
(1)特征搜索:一般在so中可以直接搜索datadiv_decode,一般很多编写解密函数进行操作是这个函数,针对这种情况,一般可以通过frida hook就可以拿到解密后的值,然后进行patch
(2)init_array中解密:字符串解密操作在init_arrray中进行,一般可以通过模拟执行init_array,然后将解密后的字符串全部保存下来
(3)jni_onload解密:在jni_onload函数中进行解密操作,这时候就要进行inlinehook拿到解密后寄存器的值,也可以进行hook,也可以使用unicorn进行操作





