一、搭建开发环境
1 pip install numpy tqdm matplotlib
1 pip install numpy tqdm matplotlib
二、准备一个数据集
1.准备环境(以openwebtext为例) 1 2 git clone https://github.com/JCPETERSON/OpenwebText.git cd OpenwebText
python版本得高一点,我用的3.12,3.8不行。
1 pip install -r requirements.txt
如果老报错版本问题就直接下(没报错就不改)
1 pip install beautifulsoup4 certifi chardet cssselect feedfinder2 feedparser htmlmin idna jieba3k lxml newspaper3k nltk numpy pandas pillow python-dateutil pytorch-pretrained-bert pytz pyyaml recordtype requests-file requests singledispatch six soupsieve spacy tinysegmenter tldextract tqdm urllib3 urlparse2 pycurl pebble chardet transformers
2.加载&预处理数据 这里面的url是已经去重了的,正常流程如下
1 2 3 4 5 6 7 8 提取 URL python extract_urls.py --single_file pushshift_dumps/RS_v2_2005-06.xz 想提取一个时间范围内的 URL python extract_urls.py --year_start 2016 --year_end 2018 去重 URL python deduplicate_urls.py --input_dir url_dumps
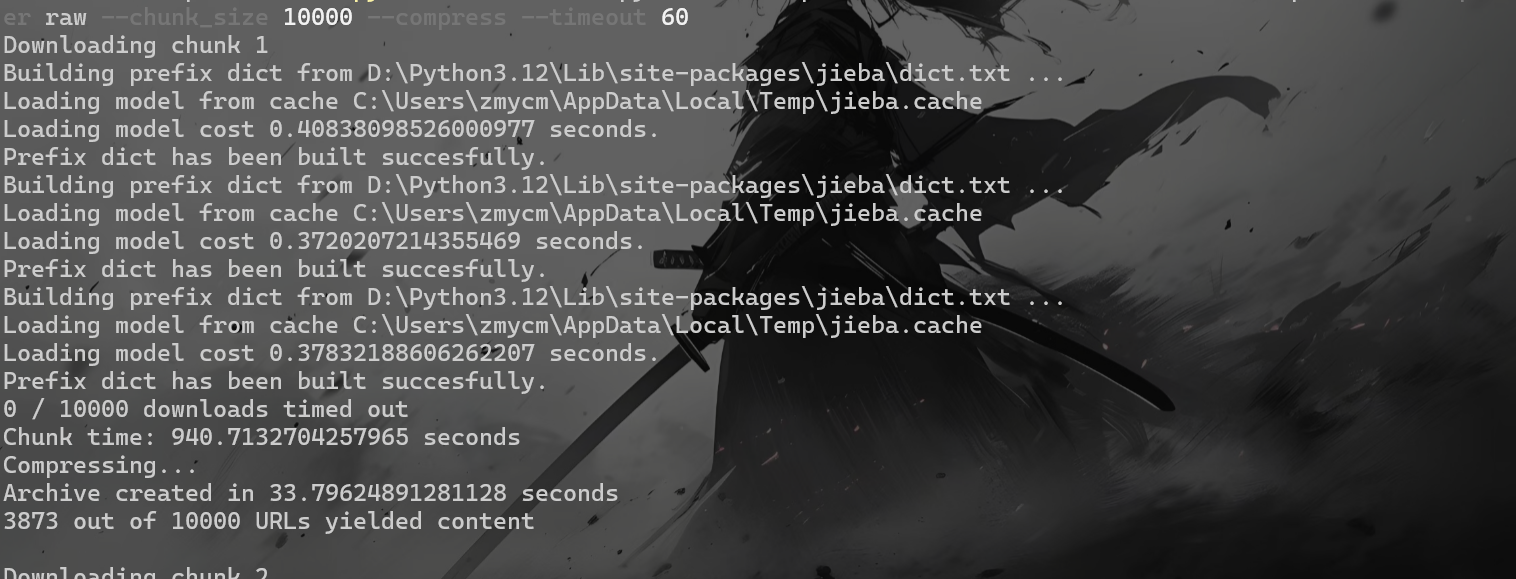
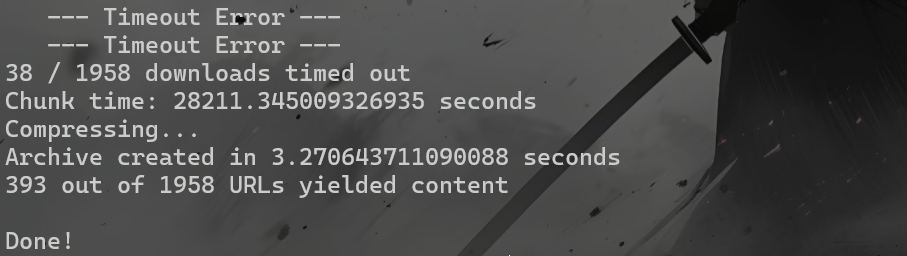
(2)、下载HTML数据 1 python312 download.py D:\Tools\openwebtext\URLs\RS_2011-01.bz2.deduped.txt --n_procs 100 --scraper raw --chunk_size 100000 --compress --timeout 30
将抓取的 HTML 页面存储在 scraped 文件夹中,并压缩存档。
等挺久的,挂着睡觉了。默认它done了就是好了()
(3)、从HTML中提取文本 1 pip install --upgrade newspaper3k
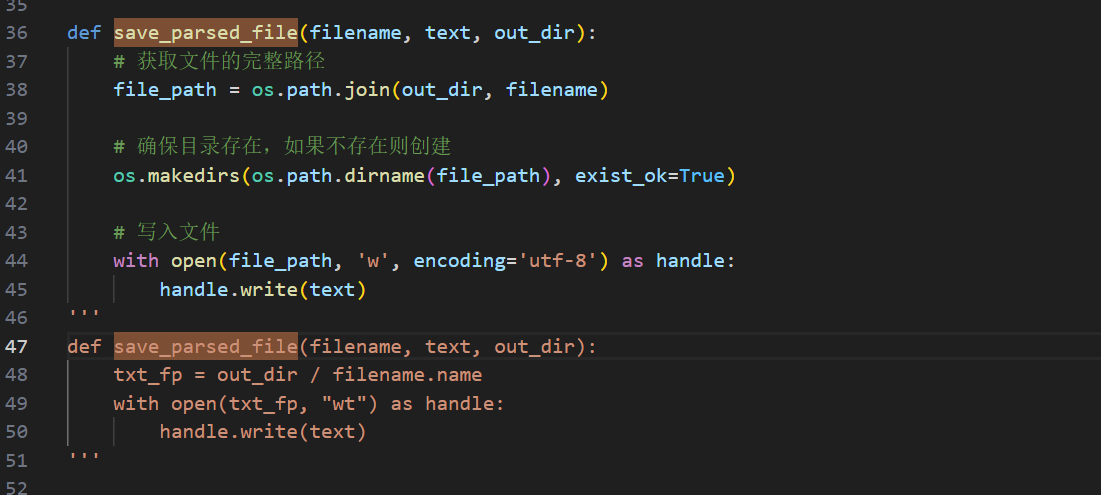
把extract_text.py里的save_parsed_file改成如下
1 2 3 4 5 6 7 8 9 10 def save_parsed_file (filename, text, out_dir ): file_path = os.path.join(out_dir, filename) os.makedirs(os.path.dirname(file_path), exist_ok=True ) with open (file_path, 'w' , encoding='utf-8' ) as handle: handle.write(text)
1 python312 extract_text.py --html_archive scraped/RS_2011-01-1_data.xz --n_procs 100
从 HTML 中提取出文本内容并保存为 .txt 文件.
–如果中间有报错重新来的话,记得把原来提取的文件删掉,文件夹在scraped里
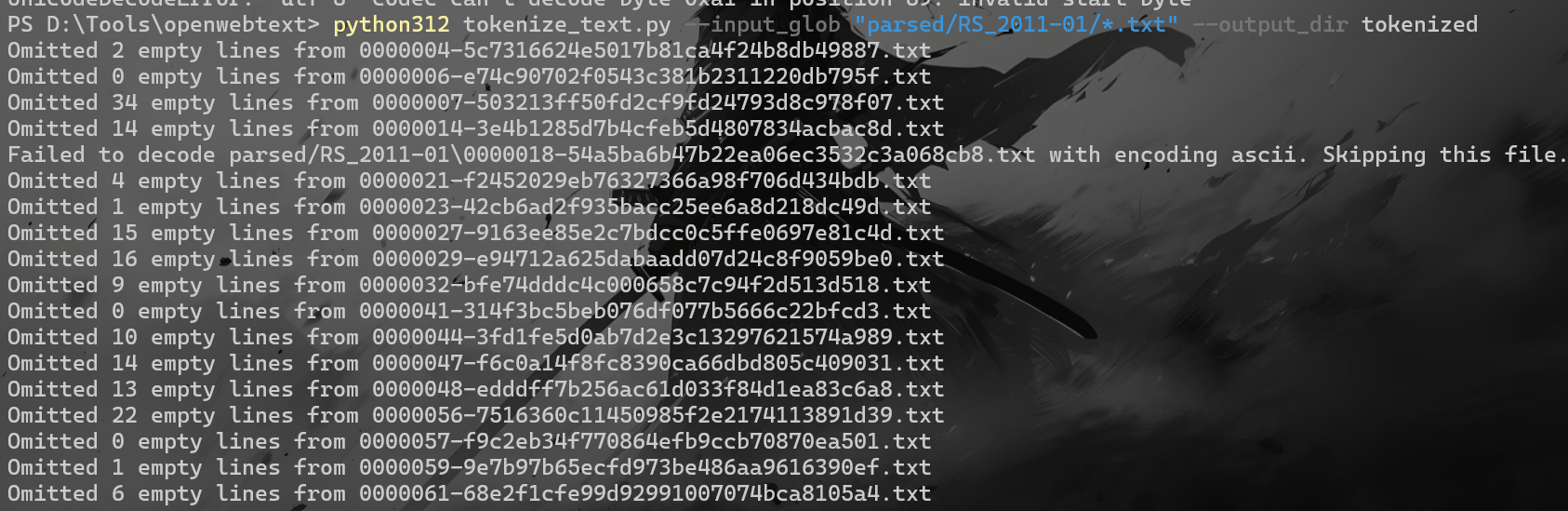
(4)、分词处理 1 python -m spacy download en_core_web_sm
更改tokenize_text.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import spacyimport ioimport argparseimport globimport osimport tqdmfrom multiprocessing import Poolfrom functools import partialimport chardetdef detect_encoding (file_path ): """检测文件的实际编码""" with open (file_path, 'rb' ) as f: raw_data = f.read(1024 ) result = chardet.detect(raw_data) return result['encoding' ] or 'utf-8' def save_tokenized_text (output_dir, filename, text ): text_file = os.path.join(output_dir, filename) os.makedirs(os.path.dirname(text_file), exist_ok=True ) with io.open (text_file, 'w' , encoding='utf-8' ) as fo: fo.write(text) def tokenizeSpacy (args ): nlp = spacy.load("en_core_web_sm" ) extraction_file_paths = glob.glob(args.input_glob) for extraction_file_path in extraction_file_paths: path, filename = os.path.split(extraction_file_path) text_file = os.path.join( args.output_dir, filename.replace('.txt' , '.tokenized.txt' )) os.makedirs(os.path.dirname(text_file), exist_ok=True ) file_encoding = detect_encoding(extraction_file_path) try : with io.open (extraction_file_path, 'r' , encoding=file_encoding) as fi, \ io.open (text_file, 'w' , encoding='utf-8' ) as fo: omitted_line_count = 0 for line in fi: if len (line.strip()) > 0 : doc = nlp(line) fo.write(' ' .join([x.text for x in doc]) + '\n' ) else : omitted_line_count += 1 print (f'Omitted {omitted_line_count} empty lines from {filename} ' ) except UnicodeDecodeError: print (f"Failed to decode {extraction_file_path} with encoding {file_encoding} . Skipping this file." ) if __name__ == '__main__' : parser = argparse.ArgumentParser() parser.add_argument('--input_glob' , type =str , default='*.txt' ) parser.add_argument('--output_dir' , type =str , default='tokenized' ) parser.add_argument('--tokenizer' , type =str , default='spacy' , choices=['spacy' , 'gpt2' ]) parser.add_argument('--combine' , type =int , default=1e8 , help ="min tokens per file in gpt2 mode" ) parser.add_argument('--file_bs' , type =int , default=10000 , help ="files per batch in gpt2 mode" ) args = parser.parse_args() os.makedirs(args.output_dir, exist_ok=True ) if args.tokenizer == 'spacy' : tokenizeSpacy(args) else : print ("GPT-2 tokenizer is not implemented in this version." )
1 python312 tokenize_text.py --input_glob "parsed/RS_2011-01/*.txt" --output_dir tokenized
三、构建和训练 GPT 类似模型 下面的文件层级关系如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 gpt_project/ ├── model/ │ ├── gpt.py │ ├── transformer_block.py ├── data/ │ ├── dataset.py │ ├── tokenizer.py # 可选 │ ├── tokenized/ # 存放所有分词好的 .txt 文件 ├── train/ │ ├── train.py # 训练代码 |——train_model/ | ├── inference.py # 生成文本
1. dataset.py 用于处理数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 import torchimport osfrom collections import Counterfrom transformers import AutoTokenizerclass TextDataset (torch.utils.data.Dataset): def __init__ (self, directory_path, seq_length, tokenizer ): self .seq_length = seq_length self .tokenizer = tokenizer self .data = [] self .vocab = {} self .inverse_vocab = {} word_counter = Counter() for filename in os.listdir(directory_path): if filename.endswith(".tokenized.txt" ): file_path = os.path.join(directory_path, filename) with open (file_path, "r" , encoding="utf-8" ) as f: words = f.read().split() word_counter.update(words) self .vocab = {word: idx + 1 for idx, (word, _) in enumerate (word_counter.items())} self .vocab['<pad>' ] = 0 self .vocab['<unk>' ] = len (self .vocab) self .inverse_vocab = {idx: word for word, idx in self .vocab.items()} for filename in os.listdir(directory_path): if filename.endswith(".tokenized.txt" ): file_path = os.path.join(directory_path, filename) with open (file_path, "r" , encoding="utf-8" ) as f: words = f.read().split() token_ids = [self .vocab.get(word, self .vocab['<unk>' ]) for word in words] self .data.append(token_ids) self .data = [self .pad_sequence(seq) for seq in self .data] def __len__ (self ): return len (self .data) def __getitem__ (self, idx ): input_text = self .data[idx] input_ids = torch.tensor(input_text) target_ids = input_ids.clone() return input_ids, target_ids def pad_sequence (self, seq ): """填充序列到 seq_length""" if len (seq) < self .seq_length: seq += [self .vocab['<pad>' ]] * (self .seq_length - len (seq)) else : seq = seq[:self .seq_length] return seq ''' def __getitem__(self, idx): input_ids = torch.tensor(self.data[idx], dtype=torch.long) # 如果输入序列长度小于 seq_length,进行填充 padding_length = self.seq_length - input_ids.size(0) if padding_length > 0: padding = torch.tensor([self.vocab['<pad>']] * padding_length, dtype=torch.long) input_ids = torch.cat([input_ids, padding], dim=0) # 设置 target_ids 为 input_ids 的下一个 token(即语言模型的训练目标) target_ids = input_ids[1:].clone() target_ids = torch.cat([target_ids, torch.tensor([self.vocab['<pad>']], dtype=torch.long)]) return input_ids, target_ids '''
2.gpt.py 实现 GPT 模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import torchimport torch.nn as nnimport osimport sysimport torch.nn.functional as Fproject_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..' )) print ("Adding to sys.path:" , project_root)sys.path.append(project_root) from model.transformer_block import TransformerBlockclass GPT (nn.Module): def __init__ (self, vocab_size, embed_size, num_layers, num_heads, hidden_dim, max_length ): super (GPT, self ).__init__() self .hidden_dim = hidden_dim class GPT (nn.Module): def __init__ (self, vocab_size, embed_size, num_heads, num_layers, max_length ): super (GPT, self ).__init__() self .embedding = nn.Embedding(vocab_size, embed_size) self .position_embedding = nn.Embedding(max_length, embed_size) self .blocks = nn.ModuleList([ TransformerBlock(embed_size, num_heads, embed_size * 4 ) for _ in range (num_layers) ]) self .fc_out = nn.Linear(embed_size, vocab_size) def forward (self, x ): batch_size, seq_length = x.shape positions = torch.arange(0 , seq_length).expand(batch_size, seq_length) x = self .embedding(x) + self .position_embedding(positions) for block in self .blocks: x = block(x) return self .fc_out(x) def generate (self, input_ids, max_length=100 , temperature=1.0 , top_k=50 ): self .eval () generated_ids = input_ids for _ in range (max_length): outputs = self (generated_ids) logits = outputs logits = logits[:, -1 , :] logits = logits / temperature if top_k > 0 : top_k_values, top_k_indices = torch.topk(logits, top_k) top_k_probs = F.softmax(top_k_values, dim=-1 ) next_token = torch.multinomial(top_k_probs, 1 ) next_token = top_k_indices.gather(-1 , next_token) else : probs = F.softmax(logits, dim=-1 ) next_token = torch.multinomial(probs, 1 ) generated_ids = torch.cat([generated_ids, next_token], dim=-1 ) return generated_ids
用于实现 GPT 模型的一个基本组件——Transformer 块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import torchimport torch.nn as nnclass AttentionHead (nn.Module): def __init__ (self, embed_size, head_size ): super ().__init__() self .q = nn.Linear(embed_size, head_size, bias=False ) self .k = nn.Linear(embed_size, head_size, bias=False ) self .v = nn.Linear(embed_size, head_size, bias=False ) self .scale = head_size ** -0.5 def forward (self, x ): q = self .q(x) k = self .k(x) v = self .v(x) scores = torch.matmul(q, k.transpose(-2 , -1 )) * self .scale attention = torch.softmax(scores, dim=-1 ) return torch.matmul(attention, v) class TransformerBlock (nn.Module): def __init__ (self, embed_size, num_heads, feed_forward_size ): super ().__init__() self .attention = nn.MultiheadAttention(embed_dim=embed_size, num_heads=num_heads) self .ff = nn.Sequential( nn.Linear(embed_size, feed_forward_size), nn.ReLU(), nn.Linear(feed_forward_size, embed_size), ) self .norm1 = nn.LayerNorm(embed_size) self .norm2 = nn.LayerNorm(embed_size) def forward (self, x ): attention_out, _ = self .attention(x, x, x) x = self .norm1(x + attention_out) ff_out = self .ff(x) return self .norm2(x + ff_out)
4. generate.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import torchfrom model.gpt import GPTfrom data.tokenizer import SimpleTokenizerdef generate_text (prompt, model, tokenizer, max_length=50 ): tokens = tokenizer.encode(prompt) input_data = torch.tensor([tokens]) model.eval () with torch.no_grad(): for _ in range (max_length): output = model(input_data) next_token = torch.argmax(output[:, -1 , :], dim=-1 ) input_data = torch.cat([input_data, next_token.unsqueeze(0 )], dim=1 ) if next_token.item() == tokenizer.word_to_idx["<END>" ]: break return tokenizer.decode(input_data[0 ].tolist()) if __name__ == "__main__" : vocab_size = 10000 embed_size = 128 num_heads = 8 num_layers = 4 max_length = 100 model = GPT(vocab_size, embed_size, num_heads, num_layers, max_length) tokenizer = SimpleTokenizer(vocab_size) tokenizer.build_vocab("This is a small test corpus <END>" ) prompt = "This is a" print (generate_text(prompt, model, tokenizer))
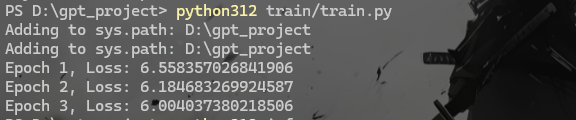
5.train.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import sysimport osproject_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..' )) print ("Adding to sys.path:" , project_root)sys.path.append(project_root) import globimport torchfrom torch.utils.data import DataLoaderfrom data.dataset import TextDatasetfrom model.gpt import GPTfrom torch.optim import AdamWfrom torch.optim.lr_scheduler import StepLRfrom transformers import AutoTokenizerfrom transformers import GPT2LMHeadModelmodel = GPT2LMHeadModel.from_pretrained('gpt2' ) def train (): tokenizer = AutoTokenizer.from_pretrained('gpt2' ) device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) model.to(device) dataset = TextDataset(directory_path="data/tokenized" , seq_length=128 , tokenizer=tokenizer) data_loader = DataLoader(dataset, batch_size=4 , shuffle=True ) optimizer = AdamW(model.parameters(), lr=1e-5 ) scheduler = StepLR(optimizer, step_size=5 , gamma=0.5 ) model.train() for epoch in range (3 ): total_loss = 0 for batch_idx, (input_ids, target_ids) in enumerate (data_loader): optimizer.zero_grad() input_ids = input_ids.to(device) target_ids = target_ids.to(device) outputs = model(input_ids, labels=target_ids) loss = outputs.loss total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0 ) optimizer.step() print (f"Epoch {epoch+1 } , Loss: {total_loss / len (data_loader)} " ) scheduler.step() torch.save(model.state_dict(), "trained_model/model.pth" ) tokenizer.save_pretrained("trained_model" ) if __name__ == "__main__" : train()
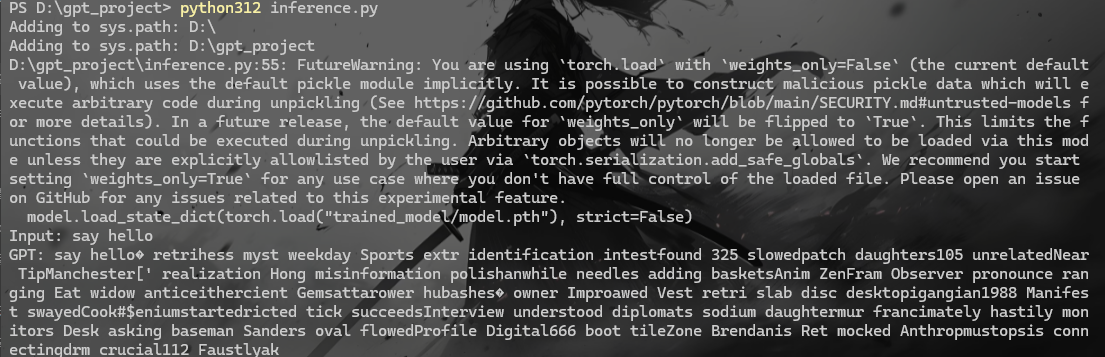
6. inference.py 这是推理脚本,用于加载训练好的模型并进行推理(生成预测)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import torchimport sysimport osimport torch.nn.functional as Fproject_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..' )) print ("Adding to sys.path:" , project_root)sys.path.append(project_root) from model.gpt import GPTfrom transformers import AutoTokenizerdef load_model (): model = GPT(vocab_size=50000 , embed_size=256 , num_layers=6 , num_heads=8 , max_length=512 ) model.load_state_dict(torch.load("trained_model/model.pth" ), strict=False ) model.eval () tokenizer = AutoTokenizer.from_pretrained('gpt2' ) return model, tokenizer def chat (): model, tokenizer = load_model() while True : text = input ("Input: " ) if text.lower() == "quit" : break input_ids = tokenizer.encode(text, return_tensors='pt' ) generated_ids = model.generate(input_ids, max_length=100 , temperature=1.0 , top_k=50 ) output_text = tokenizer.decode(generated_ids[0 ], skip_special_tokens=True ) print (f"GPT: {output_text} " ) if __name__ == "__main__" : chat()
然后运行顺序:
1 python312 train/train.py