NSSCTF easyRE(虚函数表+反调试+内联函数) [SWPU 2019]easyRE | NSSCTF
没做出来,看了佬的wp才理清思路[原创] SWPUCTF 2019 easyRE-CTF对抗-看雪-安全社区|安全招聘|kanxue.com
分析 main 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int __cdecl main (int argc, const char **argv, const char **envp) _DWORD v4[30 ]; int v5; _DWORD v6[27 ]; int v7; if ( sub_40EF90 () ) return 1 ; sub_4026C0 (0x6Cu ); sub_401FE0 (v6); v7 = 0 ; v4[29 ] = v4; sub_40F360 (v4, v6); sub_40F080 (v4[0 ], v4[1 ]); v4[28 ] = v4; sub_40F360 (v4, v6); sub_40F150 (argc, (int )argv); v5 = 0 ; v7 = -1 ; sub_4021C0 (v6); return v5; }
反调试patch掉就行
sub_401FE0 这里创建了一个虚函数表,下面的偏移是对比用的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 _DWORD *__thiscall sub_401FE0 (_DWORD *this ) int i; *this = &EASYRE::`vftable'; this[1] = 0; *((_BYTE *)this + 52) = 8; *((_BYTE *)this + 53) = 0xEA; *((_BYTE *)this + 54) = 0x58; *((_BYTE *)this + 55) = 0xDE; *((_BYTE *)this + 56) = 0x94; *((_BYTE *)this + 57) = 0xD0; *((_BYTE *)this + 58) = 0x3B; *((_BYTE *)this + 59) = 0xBE; *((_BYTE *)this + 60) = 0x88; *((_BYTE *)this + 61) = 0xD4; *((_BYTE *)this + 62) = 0x32; *((_BYTE *)this + 63) = 0xB6; *((_BYTE *)this + 64) = 0x14; *((_BYTE *)this + 65) = 0x82; *((_BYTE *)this + 66) = 0xB7; *((_BYTE *)this + 67) = 0xAF; *((_BYTE *)this + 68) = 0x14; *((_BYTE *)this + 69) = 0x54; *((_BYTE *)this + 70) = 0x7F; *((_BYTE *)this + 71) = 0xCF; qmemcpy(this + 0x12, " 03\"3 0 203\" $ ", 20); sub_4030A0(this + 0x17); sub_402DE0(this + 0x1A); for ( i = 0; i < 40; ++i ) *((_BYTE *)this + i + 12) = 0; return this; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 .rdata:004124E4 90 21 40 00 ??_7EASYRE@@6B@ dd offset sub_402190 ; DATA XREF: sub_401FE0+2B↑o .rdata:004124E4 ; sub_4021C0+A↑o .rdata:004124E4 ; sub_40F360+C↑o .rdata:004124E8 F0 21 40 00 dd offset sub_4021F0 .rdata:004124EC B0 24 40 00 dd offset sub_4024B0 .rdata:004124F0 00 25 40 00 dd offset sub_402500 .rdata:004124F4 F0 22 40 00 dd offset sub_4022F0 .rdata:004124F8 A0 23 40 00 dd offset sub_4023A0 .rdata:004124FC E0 26 40 00 dd offset sub_4026E0 .rdata:00412500 30 27 40 00 dd offset sub_402730 .rdata:00412504 E0 23 40 00 dd offset sub_4023E0 .rdata:00412508 A0 28 40 00 dd offset sub_4028A0 .rdata:0041250C 00 2A 40 00 dd offset sub_402A00 .rdata:00412510 40 24 40 00 dd offset sub_402440 .rdata:00412514 00 00 00 00 align 8
sub_40F150 找到对比函数
if ( sub_A124B0(va, input) )输出congratulations说明sub_A124B0是我们主要关注的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int sub_40F150 (int a1, int a2, ...) int v2; int v3; int v5; int v6[10 ]; int v7; va_list va; va_start (va, a2); v7 = 0 ; memset (v6, 0 , sizeof (v6)); v2 = printf (std::cout, "Please input your flag : " ); std::ostream::operator <<(v2, sub_40F8F0); sub_40F930 (std::cin, v6); if ( sub_4024B0 (v6) ) { v3 = printf (std::cout, &unk_4122F0); std::ostream::operator <<(v3, sub_40F8F0); v7 = -1 ; sub_4021C0 (va); return 1 ; } else { v5 = printf (std::cout, &unk_41231C); std::ostream::operator <<(v5, sub_40F8F0); v7 = -1 ; sub_4021C0 (va); return 0 ; } }
sub_4024B0 对照虚函数表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 BOOL __thiscall sub_D724B0 (_DWORD *this , int a2) BOOL result; this [2 ] = a2; result = 0 ; if ( (*(int (__thiscall **)(_DWORD *))(*this + 0xC ))(this ) ) { (*(void (__thiscall **)(_DWORD *))(*this + 0x18 ))(this ); if ( (*(int (__thiscall **)(_DWORD *))(*this + 0x28 ))(this ) ) return 1 ; } return result; }
简化一下就是
1 2 3 4 5 if sub_402500() sub_4026E0 () if sub_402A00 () return 1 return 0
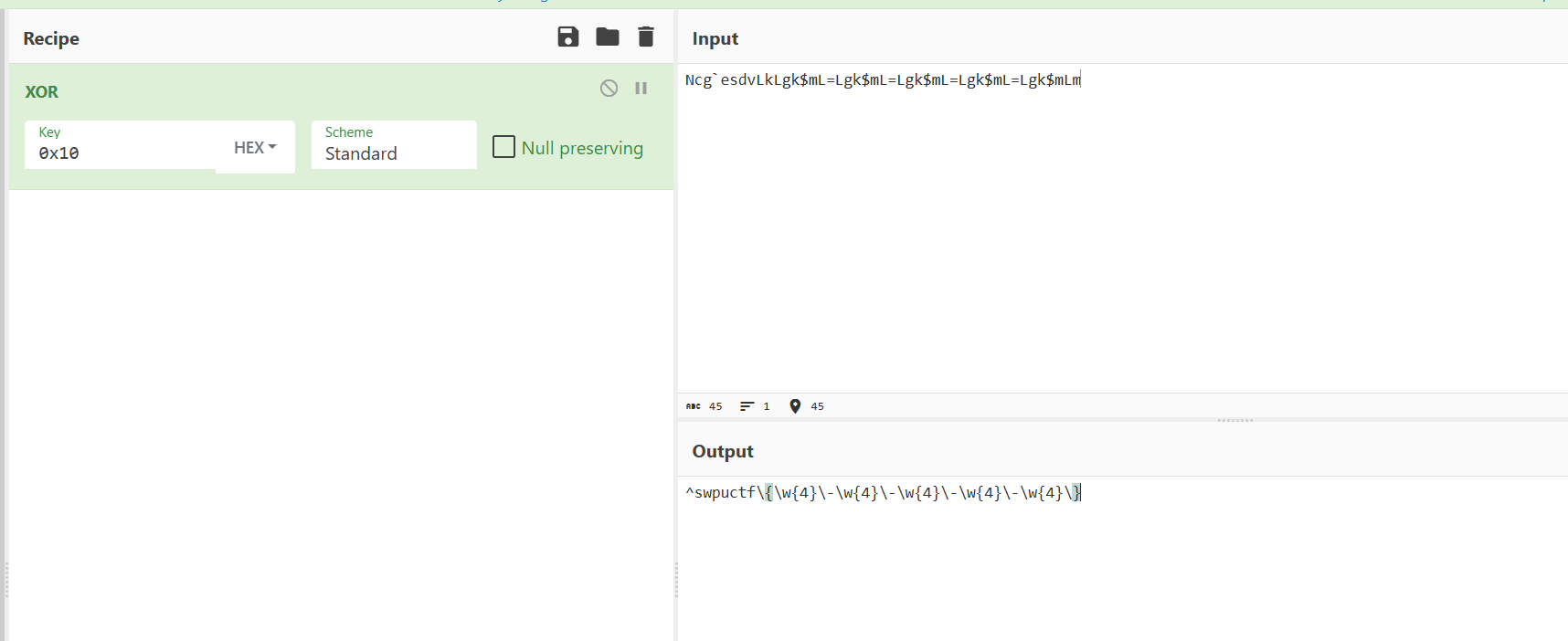
sub_D72500 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int __thiscall sub_D72500 (const char **this ) int v2; const char *v3; int i; char v6[56 ]; char v7[20 ]; char v8[48 ]; int v9; v3 = &this [2 ][strlen (this [2 ])]; strcpy (v8, "Ncg`esdvLkLgk$mL=Lgk$mL=Lgk$mL=Lgk$mL=Lgk$mLm" ); sub_D726C0 (v6, 0x38u ); sub_D72B00 (v6); v9 = 0 ; for ( i = 0 ; i < 45 ; ++i ) v8[i] ^= 0x10u ; sub_D726C0 (v7, 0x14u ); sub_D72A70 (v8, 1 ); LOBYTE (v9) = 1 ; v2 = (unsigned __int8)sub_D74260 (this [2 ], v3, v6, v7, 0 ); LOBYTE (v9) = 0 ; sub_D72A50 (v7); v9 = -1 ; sub_D726A0 (); return v2; }
1 ^swpuctf\{\w{4}\-\w{4}\-\w{4}\-\w{4}\-\w{4}\}
有点像正则表达式,估计是flag格式
sub_A12730 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 int __thiscall sub_A12730 (_DWORD *this , int a2) int v2; int v3; unsigned __int8 v4; char v6; char v7; char v8; int v10; int i; int j; int v13; int v14; int v15; int v16; int v17; int v18; v13 = 0 ; v14 = 0 ; v15 = 0 ; v16 = 0 ; v17 = 0 ; v18 = 0 ; v10 = this [2 ] + 5 * a2 + 8 ; for ( i = 0 ; i < 4 ; ++i ) *(&v13 + i) = *(i + v10); v2 = 0 ; v3 = 4 ; do { v4 = *(&v13 + v2); _DL = v4; __asm { rcl dl, 1 } *(&v15 + v2) = 1 ; v7 = 0 ; v6 = 0 ; do { v8 = v6 << 7 ; v6 = v4 & 1 ; v4 = (v4 >> 1 ) | v8; ++v7; } while ( v6 ); *(&v16 + v2++) = v7 - 1 ; --v3; } while ( v3 ); for ( j = 0 ; j < 4 ; ++j ) { *(&v14 + j) = *(&v16 + j) + *(&v15 + j); *(&v17 + j) = *(&v13 + j) << *(&v15 + j); *(&v18 + j) = (*(&v13 + j) << (8 - *(&v16 + j))) | ((*(&v13 + j) >> (8 - *(&v15 + j))) << *(&v15 + j)); } return sub_A12F80 (&v13); }
外面的dowhile其实是在计算左移几位CF为1,里面的dowhile是在计算右边0的个数
sub_A128A0 不想看了,大概看看感觉能爆破,不行再回来看
好吧还是得看
for循环嵌套if else,大概把上面加密完的flag分为两个部分处理。
前四次循环走else,对 v15 + i + 20 赋值
后四次走if,对 v17 + 0x1A 进行操作,更新 v14 并对 v15 执行位操作。
1 2 3 4 5 v17 = this; v15 = this + 3; *v15 |= *(v10 + i + 0x10) << v14; *v15 |= *(v5 + i + 0x10) << v14; *(v15 + i + 20) = *(v8 + i + 0xC) | v7;
因为我们前面得到了flag格式,可以判断出来while走5次。
一个参与了加密一个没参与
这里用了佬简化完的加密
1 2 3 4 5 6 7 8 9 10 if { v9 = sub_402DC0(v17 + 26 ); v14 -= *(unsigned __int8 *)(v9 + i); *v15 |= res3 << v14; } else { v14 -= 8 - res1; *v15 |= res2 << v14; *((_BYTE *)v15 + i + 20 ) = 0 的个数 | (16 * 左移进位位数); }
理一下逻辑
校验flag格式
加密
5次循环处理加密,两种结果,一个受字符影响一个独立存在。
对比
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 import stringdef check_1 (c ): num = 0 while True : c = c << 1 num += 1 if c & 0x100 : return num def check_0 (c ): num = 0 while True : if c & 1 : return num num += 1 c = c >> 1 def generate_0 (c ): res1 = check_0(c) + check_1(c) res2 = ((c << check_1(c)) & 0xff ) >> res1 res3 = ((c >> (8 - check_1(c))) << check_1(c)) | ((c << (8 - check_0(c)) & 0xff ) >> res1) return [res1, res2, res3] def check_part (c,s2 ): """检查字符的分类,并返回符合条件的字符""" tmp = list (set (' 03\"3 0 203\" $ ' )) tmp2=check_0(c) | (16 *check_1(c)) for i in set (s2): if tmp2 ==ord (i): return i return '' def classify (): for_each=string.ascii_lowercase+string.ascii_uppercase+string.digits second_part_res = ' 03\"3 0 203\" $ ' d=dict .fromkeys(list (set (second_part_res))) for i in list (set (second_part_res)): d[i]=[] for i in for_each: tmp=check_part(ord (i)) if tmp: d[tmp].append(i) return d def test_1 (c,v14 ): exam={c:generate_0(ord (c))} v14=v14-(8 -exam[c][0 ]) tmp=exam[c][1 ]<<v14 return tmp,v14 def test_2 (c,v14 ): exam={c:generate_0(ord (c))} v14=v14-exam[c][0 ] tmp=exam[c][2 ]<<v14 return tmp,v14 import stringdef check_1 (c ): num = 0 while True : c = c << 1 num += 1 if c & 0x100 : return num def check_0 (c ): num = 0 while True : if c & 1 : return num num += 1 c = c >> 1 def generate_0 (c ): res1 = check_0(c) + check_1(c) res2 = ((c << check_1(c)) & 0xff ) >> res1 res3 = ((c >> (8 - check_1(c))) << check_1(c)) | ((c << (8 - check_0(c)) & 0xff ) >> res1) return [res1, res2, res3] def check_part (c ): tmp = list (set (' 03\"3 0 203\" $ ' )) tmp2 = check_0(c) | (16 * check_1(c)) for i in tmp: if tmp2 == ord (i): return i return '' def classify (): for_each = string.ascii_lowercase + string.ascii_uppercase + string.digits second_part_res = ' 03\"3 0 203\" $ ' d = dict .fromkeys(list (set (second_part_res))) for i in list (set (second_part_res)): d[i] = [] for i in for_each: tmp = check_part(ord (i)) if tmp: d[tmp].append(i) return d def test_1 (c, v14 ): exam = {c: generate_0(ord (c))} v14 = v14 - (8 - exam[c][0 ]) tmp = exam[c][1 ] << v14 return tmp, v14 def test_2 (c, v14 ): exam = {c: generate_0(ord (c))} v14 = v14 - exam[c][0 ] tmp = exam[c][2 ] << v14 return tmp, v14 def calc_first_part (s ): v14 = 0x20 tmp, v14 = test_1(s[0 ], v14) tmp2, v14 = test_1(s[1 ], v14) tmp3, v14 = test_1(s[2 ], v14) tmp4, v14 = test_1(s[3 ], v14) tmp5, v14 = test_2(s[0 ], v14) tmp6, v14 = test_2(s[1 ], v14) tmp7, v14 = test_2(s[2 ], v14) tmp8, v14 = test_2(s[3 ], v14) return tmp | tmp2 | tmp3 | tmp4 | tmp5 | tmp6 | tmp7 | tmp8 def check_first_part (second_part, first_part, d ): for i in d[second_part[0 ]]: for j in d[second_part[1 ]]: for k in d[second_part[2 ]]: for m in d[second_part[3 ]]: tmp = i + j + k + m if calc_first_part(tmp) == first_part: return tmp d = classify() s2 = ' 03\"3 0 203\" $ ' s = ['08' , 'EA' , '58' , 'DE' , '94' , 'D0' , '3B' , 'BE' , '88' , 'D4' , '32' , 'B6' , '14' , '82' , 'B7' , 'AF' , '14' , '54' , '7F' , 'CF' ] flag = 'swpuctf{' for i in range (0 , 5 ): first_part = int (s[3 + 4 * i] + s[2 + 4 * i] + s[1 + 4 * i] + s[4 * i], 16 ) second_part = s2[i * 4 :i * 4 + 4 ] res = check_first_part(second_part, first_part, d) if i == 4 : flag += res break flag += res + '-' flag += '}' print (flag)
EasiestRe(双进程+自修改+背包加密) [SWPU 2019]EasiestRe | NSSCTF
分析 main 进来先看到IsDebuggerPresent,运行一下发现和直接打开的结果不一样,双进程。
1 2 3 if ( IsDebuggerPresent() ) ..... if ( CreateProcessA(Filename, 0 , 0 , 0 , 0 , 3u , 0 , 0 , &StartupInfo, &ProcessInformation) )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 int __cdecl main_0 (int argc, const char **argv, const char **envp) { PVOID lpBaseAddress; char v5; DWORD dwContinueStatus; struct _DEBUG_EVENT DebugEvent ; char v8; CONTEXT Context; HANDLE hThread; int i; SIZE_T NumberOfBytesRead[3 ]; SIZE_T NumberOfBytesWritten[3 ]; char Buffer[60 ]; char v15[40 ]; char v16[16 ]; struct _STARTUPINFOA StartupInfo ; struct _PROCESS_INFORMATION ProcessInformation ; CHAR Filename[267 ]; memset (&ProcessInformation, 0 , sizeof (ProcessInformation)); j__memset(&StartupInfo, 0 , sizeof (StartupInfo)); v16[0 ] = 0x90 ; v16[1 ] = 0x83 ; v16[2 ] = 0x7D ; v16[3 ] = 0xF8 ; v16[4 ] = 0x18 ; v16[5 ] = 0x7D ; v16[6 ] = 0x11 ; v15[0 ] = 0x90 ; v15[1 ] = 0xF ; v15[2 ] = 0xB6 ; v15[3 ] = 0x55 ; v15[4 ] = 0xF7 ; v15[5 ] = 0x8B ; v15[6 ] = 0x45 ; v15[7 ] = 8 ; v15[8 ] = 0x8B ; v15[9 ] = 4 ; v15[10 ] = 0x90 ; v15[11 ] = 0xF ; v15[12 ] = 0xAF ; v15[13 ] = 0x45 ; v15[14 ] = 0xFC ; v15[15 ] = 0x33 ; v15[16 ] = 0xD2 ; v15[17 ] = 0xF7 ; v15[18 ] = 0x75 ; v15[19 ] = 0xF8 ; v15[20 ] = 0xF ; v15[21 ] = 0xB6 ; v15[22 ] = 0x4D ; v15[23 ] = 0xF7 ; v15[24 ] = 0x8B ; v15[25 ] = 0x45 ; v15[26 ] = 0xC ; v15[27 ] = 0x89 ; v15[28 ] = 0x14 ; v15[29 ] = 0x88 ; j__memset(Buffer, 0 , 0x32u ); NumberOfBytesWritten[0 ] = 0 ; i = 0 ; v8 = 1 ; if ( IsDebuggerPresent() ) { GetStartupInfoA(&StartupInfo); GetModuleFileNameA(0 , Filename, 0x104u ); if ( CreateProcessA(Filename, 0 , 0 , 0 , 0 , 3u , 0 , 0 , &StartupInfo, &ProcessInformation) ) { v5 = 1 ; LABEL_6: while ( v5 ) { dwContinueStatus = 0x10002 ; WaitForDebugEvent(&DebugEvent, 0xFFFFFFFF ); switch ( DebugEvent.dwDebugEventCode ) { case 1u : if ( DebugEvent.u.Exception.ExceptionRecord.ExceptionCode == 0x80000003 ) { v8 = 1 ; dwContinueStatus = 0x10002 ; lpBaseAddress = DebugEvent.u.Exception.ExceptionRecord.ExceptionAddress; ReadProcessMemory( ProcessInformation.hProcess, DebugEvent.u.Exception.ExceptionRecord.ExceptionAddress, Buffer, 0x23u , NumberOfBytesRead); if ( NumberOfBytesRead[0 ] ) { for ( i = 1 ; i < 35 && Buffer[i] == 0x90 ; ++i ) ; } if ( i == 1 ) v8 = 0 ; if ( v8 ) { switch ( i ) { case 4 : Context.ContextFlags = 65543 ; hThread = OpenThread(0x1FFFFFu , 0 , DebugEvent.dwThreadId); if ( !GetThreadContext(hThread, &Context) ) goto LABEL_31; ++Context.Eip; if ( SetThreadContext(hThread, &Context) ) { dwContinueStatus = 0x10002 ; CloseHandle(hThread); } goto LABEL_33; case 5 : LABEL_31: ContinueDebugEvent(DebugEvent.dwProcessId, DebugEvent.dwThreadId, 0x80010001 ); goto LABEL_6; case 7 : WriteProcessMemory(ProcessInformation.hProcess, lpBaseAddress, v16, 7u , NumberOfBytesWritten); if ( NumberOfBytesWritten[0 ] == 7 ) { ReadProcessMemory(ProcessInformation.hProcess, lpBaseAddress, Buffer, 7u , NumberOfBytesRead); dwContinueStatus = 65538 ; } goto LABEL_33; case 30 : WriteProcessMemory(ProcessInformation.hProcess, lpBaseAddress, v15, 0x1Eu , NumberOfBytesWritten); if ( NumberOfBytesWritten[0 ] == 30 ) dwContinueStatus = 65538 ; goto LABEL_33; default : goto LABEL_33; } } dwContinueStatus = 0x80010001 ; } goto LABEL_33; case 2u : case 3u : ContinueDebugEvent(DebugEvent.dwProcessId, DebugEvent.dwThreadId, 0x10002u ); break ; case 4u : case 5u : v5 = 0 ; ContinueDebugEvent(DebugEvent.dwProcessId, DebugEvent.dwThreadId, 0x10002u ); break ; case 6u : ContinueDebugEvent(DebugEvent.dwProcessId, DebugEvent.dwThreadId, 0x10002u ); break ; default : LABEL_33: ContinueDebugEvent(DebugEvent.dwProcessId, DebugEvent.dwThreadId, dwContinueStatus); break ; } } return 0 ; } else { return 0 ; } } else { sub_F53922(); return 0 ; } }
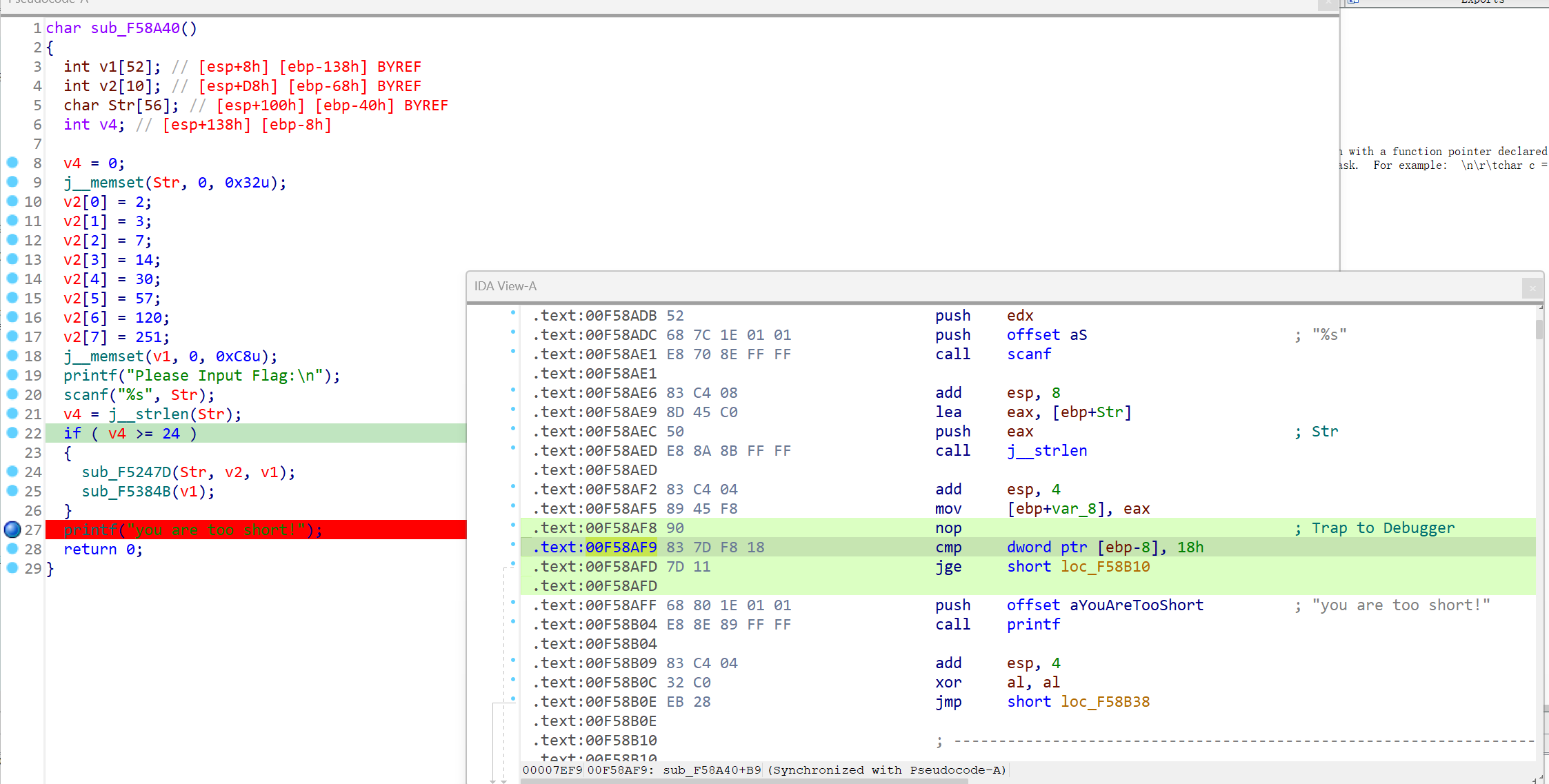
sub_F58A40 1 2 3 4 5 6 7 8 9 text:00F58AF8 int 3 ; Trap to Debugger text:00F58AF9 nop text:00F58AFA nop text:00F58AFB nop text:00F58AFC nop text:00F58AFD nop text:00F58AFE nop text:00F58AFF push offset aYouAreTooShort ; "you are too short!" text:00F58B04 call printf
根据上面的分析,遇到int 3会写入v16 7字节的数据
1 2 3 4 5 6 7 8 case 7 : WriteProcessMemory(ProcessInformation.hProcess, lpBaseAddress, v16, 7u , NumberOfBytesWritten); if ( NumberOfBytesWritten[0 ] == 7 ) { ReadProcessMemory(ProcessInformation.hProcess, lpBaseAddress, Buffer, 7u , NumberOfBytesRead); dwContinueStatus = 65538 ; } goto LABEL_33;
paste data就行
sub_F587E0
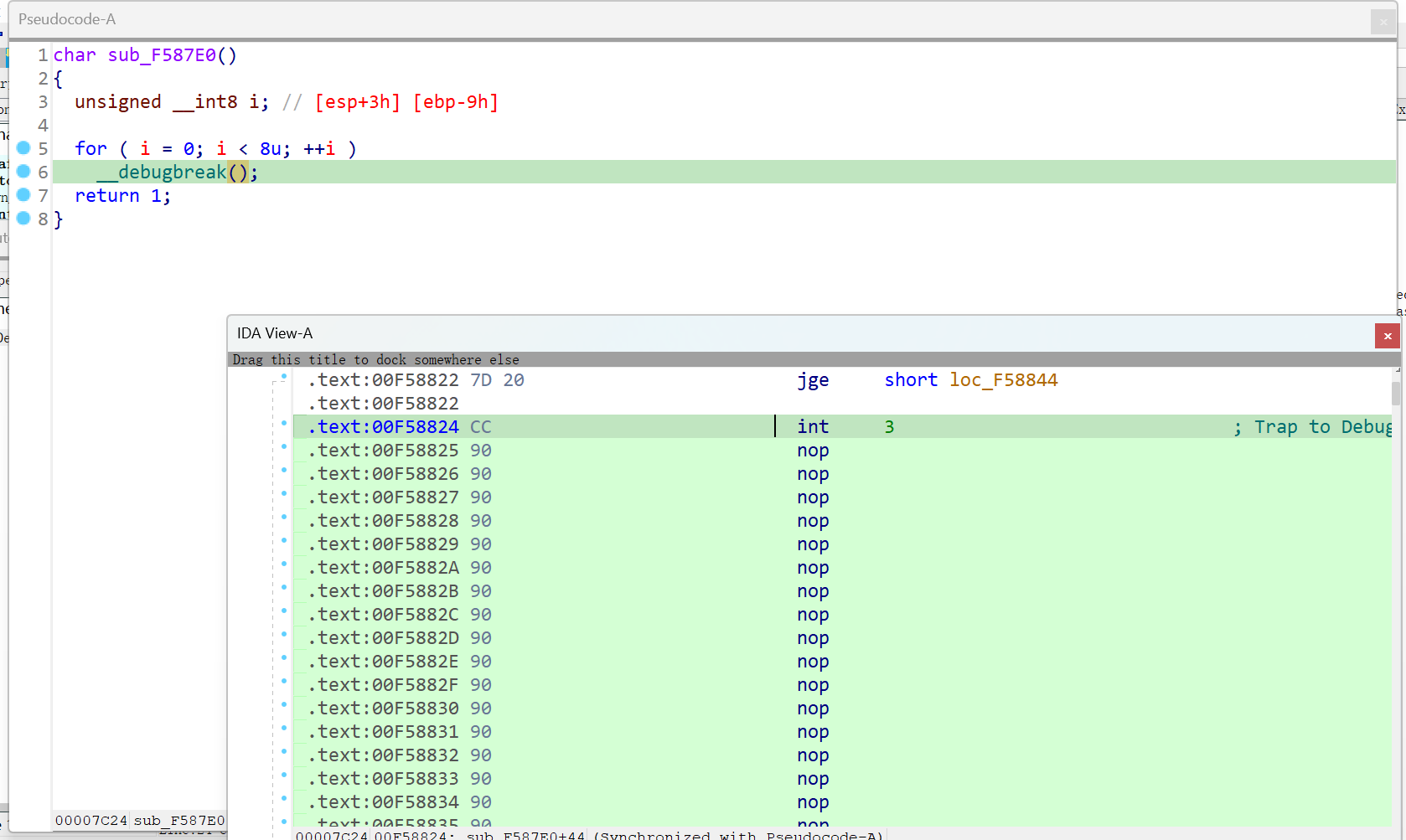
30字节的有点长,idapython吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import idaapiimport idcstart_addr = 0x00F58C45 end_addr = 0x00F58D10 data = [] for addr in range (start_addr, end_addr + 1 ): byte = idaapi.get_byte(addr) if byte != -1 : data.append(byte) stored_values = [] for i in range (0 , len (data) - 6 , 7 ): stored_values.append(data[i + 6 ]) print ("Stored values in array:" )print ("[" + ", " .join("0x{:02X}" .format (x) for x in stored_values) + "]" )
1 2 3 4 5 6 from idaapi import *from idc import *data=[0x90 , 0x0F , 0xB6 , 0x55 , 0xF7 , 0x8B , 0x45 , 0x08 , 0x8B , 0x04 , 0x90 , 0x0F , 0xAF , 0x45 , 0xFC , 0x33 , 0xD2 , 0xF7 , 0x75 , 0xF8 , 0x0F , 0xB6 , 0x4D , 0xF7 , 0x8B , 0x45 , 0x0C , 0x89 , 0x14 ,0x88 ] b=0x0F58824 for i in range (30 ): ida_bytes.patch_byte(b+i,data[i])
修完
1 2 3 4 5 6 7 8 char __cdecl sub_F587E0 (int a1, int a2) { unsigned __int8 i; for ( i = 0 ; i < 8u ; ++i ) *(a2 + 4 * i) = 41 * *(a1 + 4 * i) % 0x1EBu ; return 1 ; }
还要个in3+3个nop,根据主函数分析不管它
sub_F583C0 in3+4个nop,对应case4,main里的处理是eip+1跳过异常
在int3那里下个断点,动调一下看看程序咋处理这里的
忘了双线程了,apply patch to programm,然后运行一下exe
1 2 3 4 5 6 7 8 9 10 11 .text:0069842B ; __try { // __except at loc_69845A .text:0069842B C7 45 FC 00 00 00 00 mov [ebp+ms_exc.registration.TryLevel], 0 .text:00698432 CC int 3 ; Trap to Debugger .text:00698433 90 nop .text:00698434 90 nop .text:00698435 90 nop .text:00698436 90 nop .... .text:0069845A loc_69845A: ; DATA XREF: .rdata:stru_7783E8↓o .text:0069845A ; __except(loc_698454) // owned by 69842B .text:0069845A 8B 65 E8 mov esp, [ebp+ms_exc.old_esp]
这里直接跳到了loc_69845A,有点像密文密钥之类的,同样的我们keypatch in3
然后就是解密了,背包加密网上随便找个脚本改改
swpuctf{y0u_@re_s0_coo1}
[zer0pts 2020]vmlog(vm) [zer0pts 2020]vmlog | NSSCTF
拿到vm.py和log.txt,vm.py实现了一个自定义的指令集,行为取决于program变量和输入。做vm题的常规思路就是把汇编打印出来看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import sysfrom program import programreg = 0 mem = [0 for _ in range (10 )] p = 0 pc = 0 buf = "" print (program)while pc < len (program): op = program[pc] if op == "+" : reg += 1 print (f"{pc} add reg 1 #reg={reg} " ) elif op == "-" : reg -= 1 print (f"{pc} sub reg 1 #reg={reg} " ) elif op == "*" : reg *= mem[p] print (f"{pc} mul reg mem[{p} ] #reg={reg} " ) elif op == "%" : reg = mem[p] % reg print (f"{pc} mod reg mem[{p} ] #reg={reg} " ) elif op == "l" : reg = mem[p] print (f"{pc} mov reg mem[{p} ] #reg={reg} ,p={p} " ) elif op == "s" : mem[p] = reg print (f"{pc} mov mem[{p} ] reg #mem={mem} ,p={p} " ) elif op == ">" : p = (p + 1 ) % 10 print (f"{pc} inc p 1 #p={p} " ) elif op == "<" : p = (p - 1 ) % 10 print (f"{pc} dec p 1 #p={p} " ) elif op == "," : a = sys.stdin.buffer.read(1 ) print (f"{pc} getchar" ) if not a: reg = 0 print (f"{pc} mov, reg 0 #reg={reg} " ) else : reg += ord (a) print (f"{pc} mov, reg {ord (a)} #input #reg={reg} " ) elif op == "p" : buf += str (reg) print (f"{pc} buf+=str(reg)" ) elif op == "[" : print (f"{pc} cmp reg 0" ) if reg == 0 : cnt = 1 while cnt != 0 : pc += 1 if program[pc] == "[" : cnt += 1 if program[pc] == "]" : cnt -= 1 print (f"{pc} jz " ) elif op == "]" : print (f"{pc} cmp reg 0" ) if reg != 0 : cnt = 1 while cnt != 0 : pc -= 1 if program[pc] == "[" : cnt -= 1 if program[pc] == "]" : cnt += 1 print (f"{pc} jnz " ) elif op == "M" : print (mem) pc += 1 print (buf)print ("--------------------------------" )print ("--------------------------------" )print ("--------------------------------" )
给的log.txt是program+运行日志
自己再定义一个program.py
1 program = "M+s+>s>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[s<<l>*<s>>l-]<<l-s>l*-s*-s*-s*-s*-s*-s>l*+++++s*-----s****s>>l+s[Ml-s<<l>,[<<*>>s<<<l>>>%<s>>l<s>l+s<l]>l]<<lp"
1 2 M+s+>s>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[s<<l>*<s>>l-]<<l-s >l*-s*-s*-s*-s*-s*-s
M
s 和 l
:将值存储到内存或加载到寄存器。
mem[0] 被设置为一个大值(262−12^{62} - 1262−1),通常用于模运算。mem[1] 被设置为 2(基数 r)。mem[2] 被设置为 1(初始哈希值 h)。
推断
这种初始化方式非常典型,常见于滚动哈希算法的实现。
[ ,<<\*h 加上输入字符后,乘以基数 r。%m 取模,防止哈希值溢出。推断
这是滚动哈希算法的核心公式: h=(h+input)⋅rmod mh = (h + \text{input}) \cdot r \mod mh=(h+input)⋅rmodm
1 [Ml-s<<l>,[<<*>>s<<<l>>>%<s>>l<s>l+s<l]>l]<<lp
循环核心
[Ml-s<<l>:开始新一轮的哈希值更新,标志位控制。,[<<*>>s<<<l>>>%<s:对每个输入字符进行滚动哈希更新。>l+s<l]:设置标志位,继续下一轮输入处理。
推断
滚动哈希的本质是对输入字符的逐个处理,结合乘法、加法和模运算。
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 flag = "" with open (r"D:\LeStoreDownload\webpage\CTF\nssctf\[zer0pts 2020]vmlog\tmp\log.txt" ) as f: prev_h = None for l in f: try : arr = eval (l.strip()) if arr[4 ] == 1 : if prev_h: for i in range (256 ): if (prev_h + i) * arr[1 ] % arr[0 ] == arr[2 ]: flag += chr (i) break prev_h = arr[2 ] except : pass print (flag)